Masked Trajectory Models for Prediction, Representation, and Control
- Philipp Wu1,2
- Arjun Majumdar†,3
- Kevin Stone†,1
- Yixin Lin†,1
- Igor Mordatch4
- Pieter Abbeel2
- Aravind Rajeswaran1
- 1 Meta
- 2 UC Berkeley
- 3 Georgia Tech
- 4 Google
- † denotes equal second author contribution

Abstract
We introduce Masked Trajectory Models~(MTM) as a generic abstraction for sequential decision making. MTM takes a trajectory, such as a state-action sequence, and aims to reconstruct the trajectory conditioned on random subsets of the same trajectory. By training with a highly randomized masking pattern, MTM learns versatile networks that can take on different roles or capabilities, by simply choosing appropriate masks at inference time. For example, the same MTM network can be used as a forward dynamics model, inverse dynamics model, or even an offline RL agent. Through extensive experiments in several continuous control tasks, we show that the same MTM network -- i.e. same weights -- can match or outperform specialized networks trained for the aforementioned capabilities. Additionally, we find that state representations learned by MTM can significantly accelerate the learning speed of traditional RL algorithms. Finally, in offline RL benchmarks, we find that MTM is competitive with specialized offline RL algorithms, despite MTM being a generic self-supervised learning method without any explicit RL components.
Highlights
MTM as a general purpose model
MTM is trained with a randomized masking pattern and an autoregressive prediction constraint, shown in the orange box. The same model trained with MTM can be used zero-shot for multiple purposes including inverse dynamics, forward dynamics, imitation learning, offline RL, and representation learning simply by changing the masking pattern at inference time. These different capabilities are shown in gray boxes.
MTM as a heteromodal learner
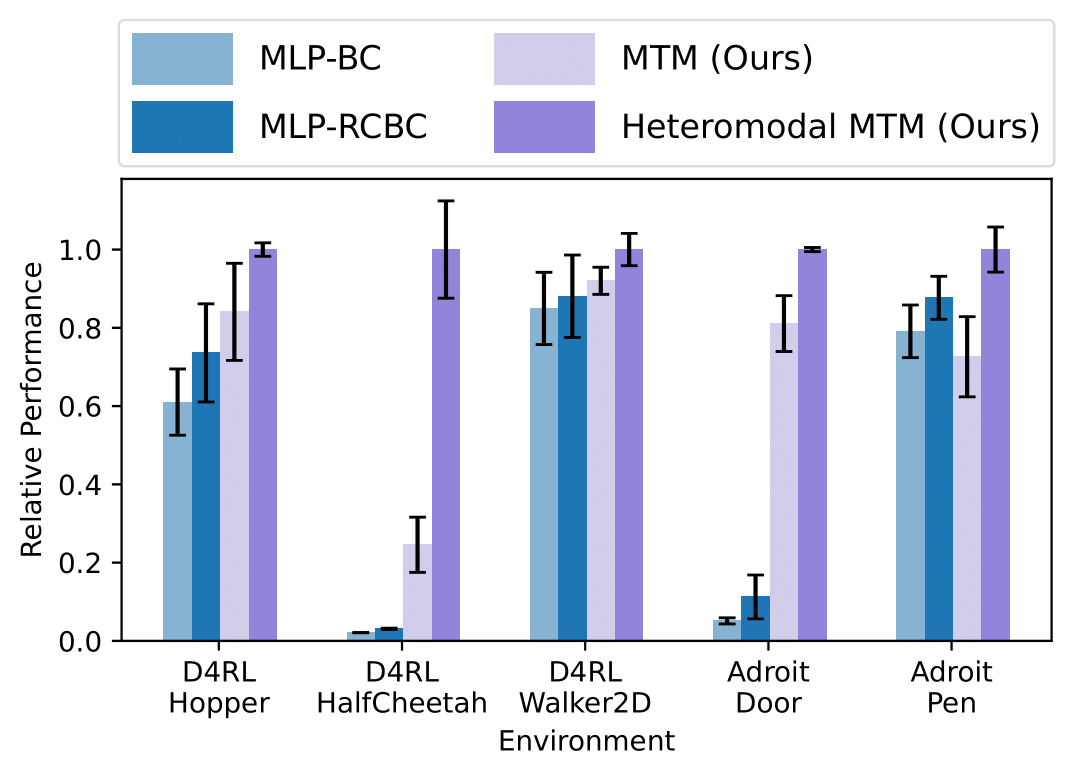 MTM is uniquely capable of learning from heteromodal datasets, where the dataset may contain trajectories with some missing data modes, such as actions.
We train MTM on a dataset where only a small fraction of the data have action labels and show that MTM is able to improve performance by training on the trajectories with missing actions, a capability that typical models lack.
MTM is uniquely capable of learning from heteromodal datasets, where the dataset may contain trajectories with some missing data modes, such as actions.
We train MTM on a dataset where only a small fraction of the data have action labels and show that MTM is able to improve performance by training on the trajectories with missing actions, a capability that typical models lack.
MTM as a sample efficient learner
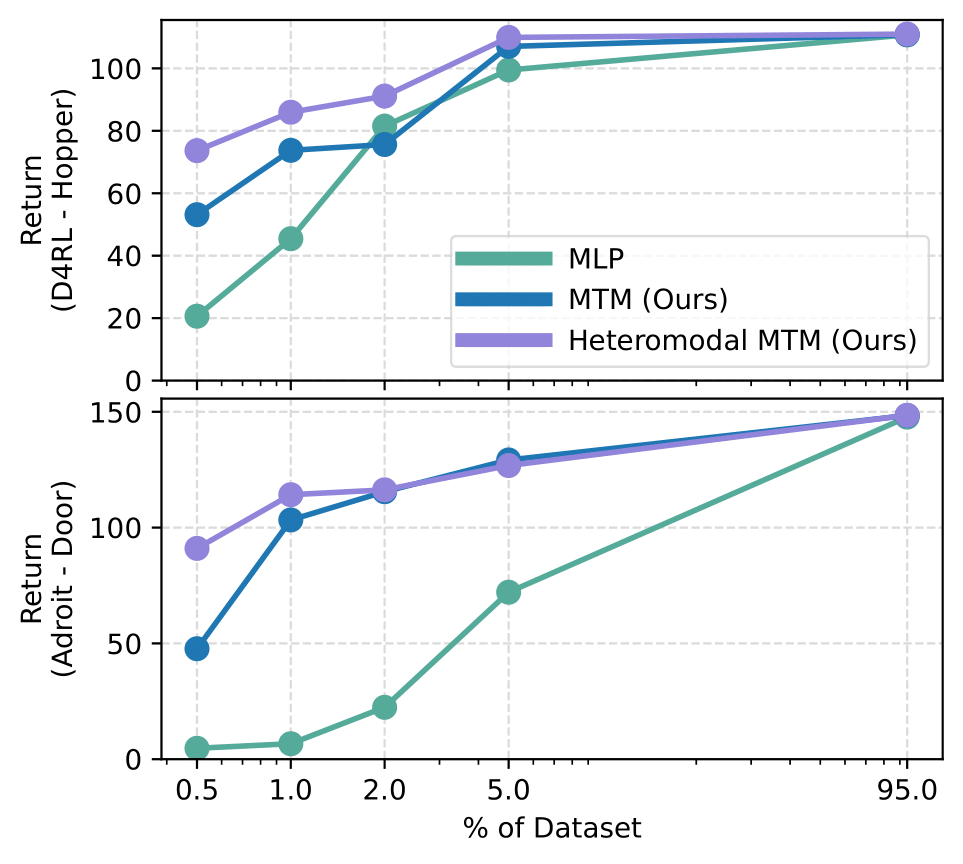 MTM is sample efficient. We show that MTM can learn from less data and perform better than baselines.
MTM is sample efficient. We show that MTM can learn from less data and perform better than baselines.
MTM as a representation learner
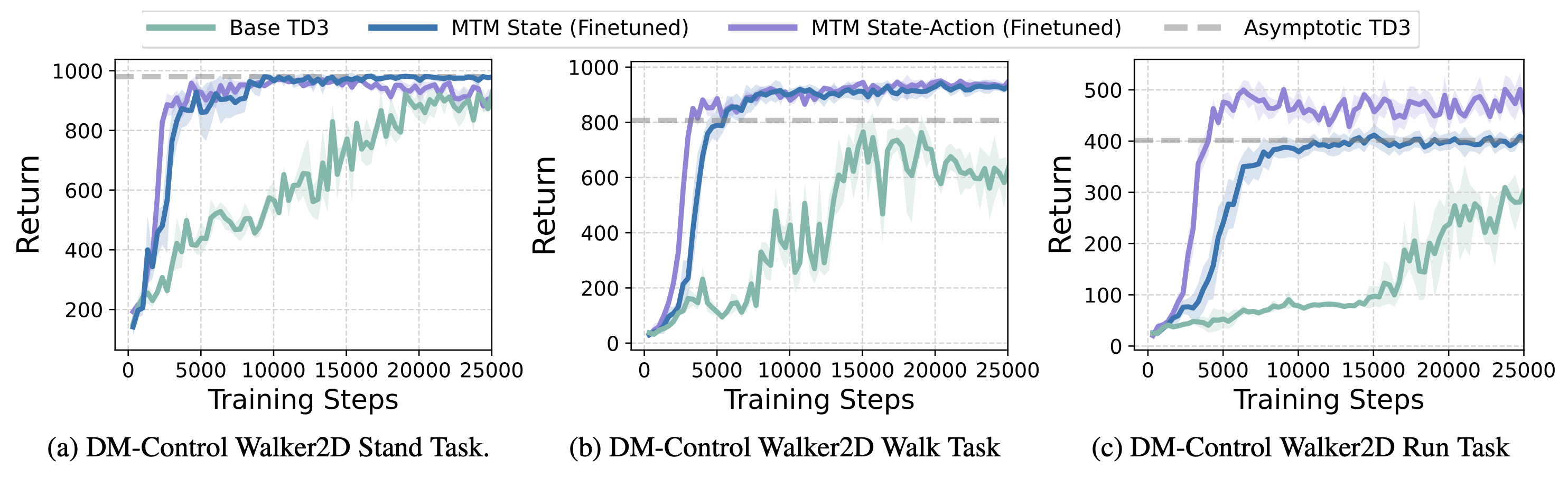 MTM learns representations that can be used to accelerate downstream RL. Here we show how using state representations and state-action representations learned by MTM can accelerate the learning speed of TD3 in offline settings.
MTM learns representations that can be used to accelerate downstream RL. Here we show how using state representations and state-action representations learned by MTM can accelerate the learning speed of TD3 in offline settings.
Acknowledgements
We would like to thank Kevin Zakka for providing the website template, which is taken from his work RoboPianist.